文章目录
- 一、Kerberos入门与使用
- 1、Kerberos概述
- 1.1 什么是Kerberos
- 1.2 Kerberos术语
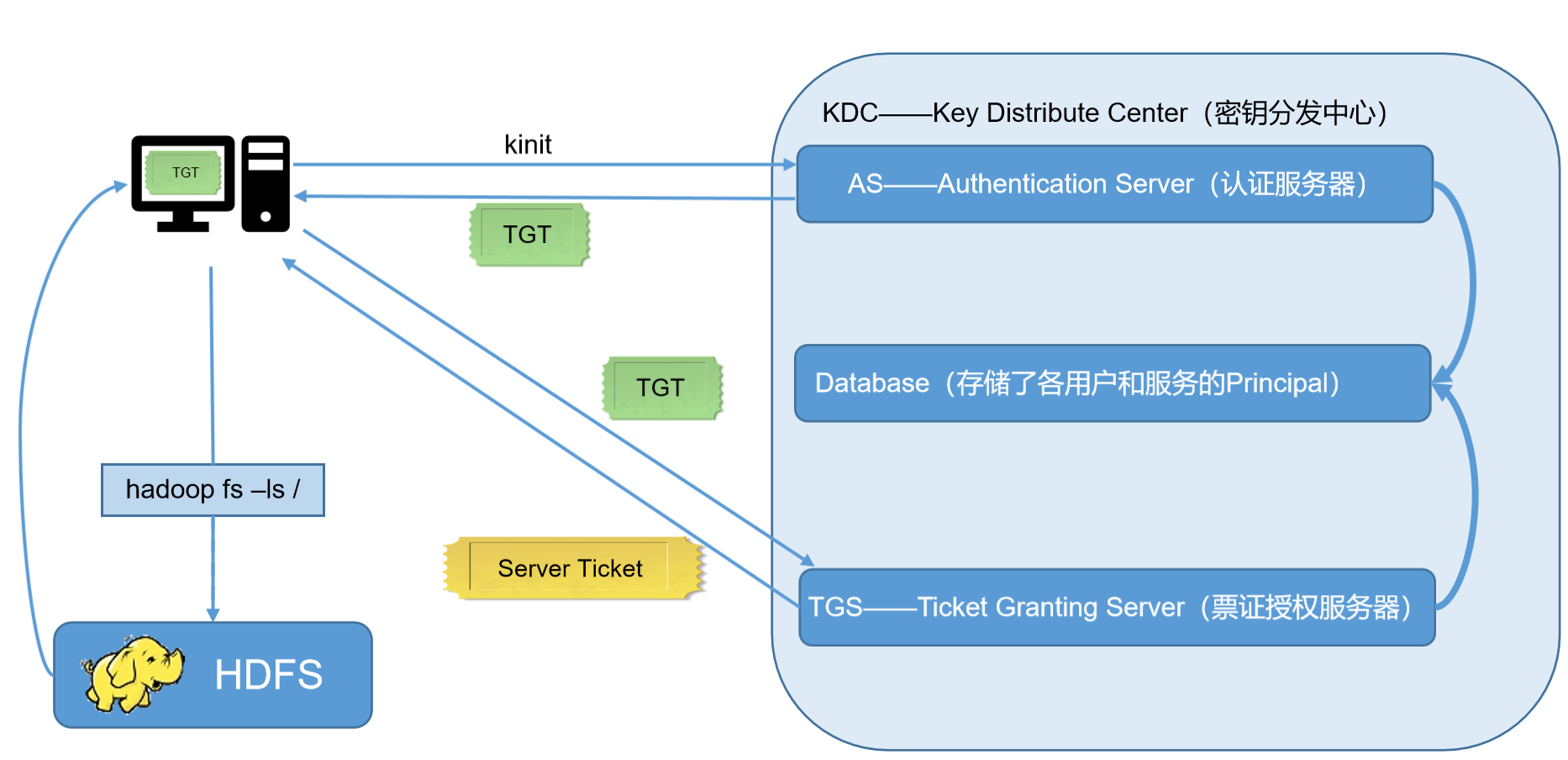
- 1.3 Kerberos认证原理
- 2、Kerberos安装
- 2.1 安装Kerberos相关服务
- 2.2 修改配置文件
- 2.3 其他配置与启动
- 3、Kerberos使用概述
- 3.1 Kerberos数据库操作
- 3.2 Kerberos认证操作
- 二、Hadoop Kerberos配置
- 1、创建Hadoop系统用户
- 2、Hadoop Kerberos配置
- 2.1 为Hadoop各服务创建Kerberos主体(Principal)
- 2.2 修改Hadoop配置文件
- 2.3 配置HDFS使用HTTPS安全传输协议
- 2.4 配置Yarn使用LinuxContainerExecutor
- 3、安全模式下启动Hadoop集群
- 3.1 修改特定本地路径权限
- 3.2 启动HDFS
- 3.3 改HDFS特定路径访问权限
- 3.4 启动Yarn
- 3.5 启动HistoryServer
- 4、启动遇坑详解
- 4.1 DataNode无法连接上NameNode 提示 : GSS initiate failed
- 4.2 Hadoop集成kerberos后,报错:AccessControlException
- 5、安全集群使用说明
- 5.1 用户要求
- 5.2 访问HDFS集群文件
- 5.3 提交MapReduce任务
- 三、Hive安全认证
- 1、Hive用户认证配置
- 1.1 创建Hive系统用户和Kerberos主体
- 1.2 配置认证
- 1.3 启动hiveserver2
- 2、Hive Kerberos认证使用说明
- 2.1 beeline客户端
- 2.2 DataGrip客户端
- 四、安全环境实战
- 1、数仓全流程改造
- 1.1 用户准备
- 1.2 数据采集通道修改
- 1.3 修改HDFS特定路径所有者
- 1.4 Azkaban举例
- 2、即席查询之Presto
- 2.1 改动说明
- 2.2 用户准备
- 2.3 创建HTTPS协议所需的密钥对
- 2.4 修改Presto Coordinator配置文件
- 2.5 修改Hive Connector配置文件
- 2.6 配置客户端Kerberos主体到用户名之间的映射规则
- 2.7 配置Presto代理用户
- 2.8 重启Presto集群
- 2.9 客户端认证访问Presto集群
- 3、即席查询之Kylin
- 3.1 改动说明
- 3.2 HBase开启Kerberos认证
- 3.3 Kylin进行Kerberos认证
一、Kerberos入门与使用
hadoop官网:https://hadoop.apache.org/docs/r3.1.3/hadoop-project-dist/hadoop-common/SecureMode.html
1、Kerberos概述
1.1 什么是Kerberos
Kerberos是一种计算机网络认证协议,用来在非安全网络中,对个人通信以安全的手段进行身份认证。这个词又指麻省理工学院为这个协议开发的一套计算机软件。软件设计上采用客户端/服务器结构,并且能够进行相互认证,即客户端和服务器端均可对对方进行身份认证。可以用于防止窃听、防止重放攻击、保护数据完整性等场合,是一种应用对称密钥体制进行密钥管理的系统
1.2 Kerberos术语
Kerberos中有以下一些概念需要了解:
- KDC(Key Distribute Center):密钥分发中心,负责存储用户信息,管理发放票据
- Realm:Kerberos所管理的一个领域或范围,称之为一个Realm
- Rrincipal:Kerberos所管理的一个用户或者一个服务,可以理解为Kerberos中保存的一个账号,其格式通常如下:primary**/**instance@realm
- keytab:Kerberos中的用户认证,可通过密码或者密钥文件证明身份,keytab指密钥文件
1.3 Kerberos认证原理
2、Kerberos安装
2.1 安装Kerberos相关服务
# 需要进入root用户
# 选择集群中的一台主机(hadoop102)作为Kerberos服务端,安装KDC,所有主机都需要部署Kerberos客户端
# 服务端主机执行以下安装命令,主机器安装
yum install -y krb5-server
# 客户端主机执行以下安装命令,三台机器分别安装
yum install -y krb5-workstation krb5-libs
2.2 修改配置文件
# 服务端主机(hadoop102)
vim /var/kerberos/krb5kdc/kdc.conf
# 修改如下内容,EXAMPLE.COM可以修改成自己的,这里我就暂时不修改了
[kdcdefaults]
kdc_ports = 88
kdc_tcp_ports = 88
[realms]
EXAMPLE.COM = {
#master_key_type = aes256-cts
acl_file = /var/kerberos/krb5kdc/kadm5.acl
dict_file = /usr/share/dict/words
admin_keytab = /var/kerberos/krb5kdc/kadm5.keytab
supported_enctypes = aes256-cts:normal aes128-cts:normal des3-hmac-sha1:normal arcfour-hmac:normal camellia256-cts:normal camellia128-cts:normal des-hmac-sha1:normal des-cbc-md5:normal des-cbc-crc:normal
}
# 客户端主机(所有主机)
# 修改/etc/krb5.conf文件
vim /etc/krb5.conf
# Configuration snippets may be placed in this directory as well
includedir /etc/krb5.conf.d/
[logging]
default = FILE:/var/log/krb5libs.log
kdc = FILE:/var/log/krb5kdc.log
admin_server = FILE:/var/log/kadmind.log
[libdefaults]
dns_lookup_realm = false
dns_lookup_kdc = false
ticket_lifetime = 24h
renew_lifetime = 7d
forwardable = true
rdns = false
pkinit_anchors = FILE:/etc/pki/tls/certs/ca-bundle.crt
default_realm = EXAMPLE.COM
#default_ccache_name = KEYRING:persistent:%{uid}
[realms]
EXAMPLE.COM = {
kdc = hadoop102
admin_server = hadoop102
}
[domain_realm]
# .example.com = EXAMPLE.COM
# example.com = EXAMPLE.COM
2.3 其他配置与启动
# 初始化KDC数据库
# 在服务端主机(hadoop102)执行以下命令,并根据提示输入密码(123456)
kdb5_util create -s
# 修改管理员权限配置文件
# 在服务端主机(hadoop102)修改/var/kerberos/krb5kdc/kadm5.acl文件
*/admin@EXAMPLE.COM *
# 启动Kerberos相关服务
# 在主节点(hadoop102)启动KDC,并配置开机自启
systemctl start krb5kdc
systemctl enable krb5kdc
# 在主节点(hadoop102)启动Kadmin,该服务为KDC数据库访问入口
systemctl start kadmin
systemctl enable kadmin
# 创建Kerberos管理员用户
# 在KDC所在主机(hadoop102),执行以下命令,并按照提示输入密码
kadmin.local -q "addprinc admin/admin"
3、Kerberos使用概述
3.1 Kerberos数据库操作
# 本地登录(无需认证)
kadmin.local
# 远程登录(需进行主体认证,认证操作见下文)
kadmin
# 创建Kerberos主体
# 登录数据库,输入以下命令,并按照提示输入密码
addprinc test
# 也可通过以下shell命令直接创建主体
kadmin.local -q"addprinc test"
# 修改主体密码
cpw test
# 查看所有主体
list_principals
3.2 Kerberos认证操作
# 密码认证
# 使用kinit进行主体认证,并按照提示输入密码
kinit test
# 查看认证凭证
klist
# 密钥文件认证
# 生成主体test的keytab文件到指定目录/root/test.keytab
kadmin.local -q "xst -norandkey -k /root/test.keytab test@EXAMPLE.COM"
# 注:-norandkey的作用是声明不随机生成密码,若不加该参数,会导致之前的密码失效
# 使用keytab进行认证
kinit -kt /root/test.keytab test
# 查看认证凭证
klist
# 销毁凭证
kdestroy
klist
一些常用操作
# 1、密码形式创建kdc用户
sudo kadmin.local -q "addprinc -pw ${pwd} ${kdcPrinc}"
# 2、keytab形式创建kdc用户
sudo kadmin.local -q "ktadd -norandkey -k ${kdcPath} ${kdcPrinc}"
# 3、删除kdc用户
sudo kadmin.local -q "delprinc -force ${kdcPrinc}"
# 4、修改kdc用户密码
sudo kadmin.local -q "cpw -pw ${newpwd} ${kdcPrinc}"
# 5、销毁票据
sudo su ${linuxUserName} kdestroy
# 6、认证票据
sudo su ${linuxUserName} kinit
# 7、查看票据缓存文件目录地址
sudo su ${linuxUserName} klist
# 8、查找某个目录下是否有该文件
find ${kdcPath} -name ${keytabFile}
二、Hadoop Kerberos配置
1、创建Hadoop系统用户
为Hadoop开启Kerberos,需为不同服务准备不同的用户,启动服务时需要使用相应的用户。须在所有节点创建以下用户和用户组
| User:Group | Daemons |
|---|---|
| hdfs:hadoop | NameNode, Secondary NameNode, JournalNode, DataNode |
| yarn:hadoop | ResourceManager, NodeManager |
| mapred:hadoop | MapReduce JobHistory Server |
# 创建hadoop组,分别在三台机器创建
groupadd hadoop
# 创建各用户并设置密码,分别在三台机器创建
useradd hdfs -g hadoop
echo hdfs | passwd --stdin hdfs
useradd yarn -g hadoop
echo yarn | passwd --stdin yarn
useradd mapred -g hadoop
echo mapred | passwd --stdin mapred
2、Hadoop Kerberos配置
2.1 为Hadoop各服务创建Kerberos主体(Principal)
主体格式如下:ServiceName/HostName@REALM,例如dn/hadoop102@EXAMPLE.COM
| 服务 | 所在主机 | 主体(Principal) |
|---|---|---|
| NameNode | hadoop102 | nn/hadoop102 |
| DataNode | hadoop102 | dn/hadoop102 |
| DataNode | hadoop103 | dn/hadoop103 |
| DataNode | hadoop104 | dn/hadoop104 |
| Secondary NameNode | hadoop104 | sn/hadoop104 |
| ResourceManager | hadoop103 | rm/hadoop103 |
| NodeManager | hadoop102 | nm/hadoop102 |
| NodeManager | hadoop103 | nm/hadoop103 |
| N****odeManager | hadoop104 | nm/hadoop104 |
| JobHistory Server | hadoop102 | jhs/hadoop102 |
| W****eb UI | hadoop102 | HTTP/hadoop102 |
| W****eb UI | hadoop103 | HTTP/hadoop103 |
| W****eb UI | hadoop104 | HTTP/hadoop104 |
创建主体说明
# 为服务创建的主体,需要通过密钥文件keytab文件进行认证,故需为各服务准备一个安全的路径用来存储keytab文件
mkdir /etc/security/keytab/
chown -R root:hadoop /etc/security/keytab/
chmod 770 /etc/security/keytab/
# 管理员主体认证
# 为执行创建主体的语句,需登录Kerberos 数据库客户端,登录之前需先使用Kerberos的管理员用户进行认证,执行以下命令并根据提示输入密码
kinit admin/admin
# 登录数据库客户端
kadmin
# 执行创建主体的语句
kadmin: addprinc -randkey test/test
kadmin: xst -k /etc/security/keytab/test.keytab test/test
# ======说明======
# (1)addprinc test/test:作用是新建主体
# addprinc:增加主体
# -randkey:密码随机,因hadoop各服务均通过keytab文件认证,故密码可随机生成
# test/test:新增的主体
# (2)xst -k /etc/security/keytab/test.keytab test/test:作用是将主体的密钥写入keytab文件
# xst:将主体的密钥写入keytab文件
# -k /etc/security/keytab/test.keytab:指明keytab文件路径和文件名
# test/test:主体
# 为方便创建主体,可使用如下命令
kadmin -padmin/admin -wadmin -q"addprinc -randkey test/test"
kadmin -padmin/admin -wadmin -q"xst -k /etc/security/keytab/test.keytab test/test"
# 说明:
# -p:主体
# -w:密码
# -q:执行语句
# 操作主体的其他命令,可参考官方文档,地址如下:
# http://web.mit.edu/kerberos/krb5-current/doc/admin/admin_commands/kadmin_local.html#commands
开始创建主体
# 在所有节点创建keytab文件目录,三台机器执行
mkdir /etc/security/keytab/
chown -R root:hadoop /etc/security/keytab/
chmod 770 /etc/security/keytab/
# ==========以下命令在hadoop102节点执行============
kadmin -padmin/admin -wadmin -q"addprinc -randkey nn/hadoop102"
kadmin -padmin/admin -wadmin -q"xst -k /etc/security/keytab/nn.service.keytab nn/hadoop102"
kadmin -padmin/admin -wadmin -q"addprinc -randkey dn/hadoop102"
kadmin -padmin/admin -wadmin -q"xst -k /etc/security/keytab/dn.service.keytab dn/hadoop102"
kadmin -padmin/admin -wadmin -q"addprinc -randkey nm/hadoop102"
kadmin -padmin/admin -wadmin -q"xst -k /etc/security/keytab/nm.service.keytab nm/hadoop102"
kadmin -padmin/admin -wadmin -q"addprinc -randkey jhs/hadoop102"
kadmin -padmin/admin -wadmin -q"xst -k /etc/security/keytab/jhs.service.keytab jhs/hadoop102"
kadmin -padmin/admin -wadmin -q"addprinc -randkey HTTP/hadoop102"
kadmin -padmin/admin -wadmin -q"xst -k /etc/security/keytab/spnego.service.keytab HTTP/hadoop102"
# ==========以下命令在hadoop103节点执行============
kadmin -padmin/admin -wadmin -q"addprinc -randkey rm/hadoop103"
kadmin -padmin/admin -wadmin -q"xst -k /etc/security/keytab/rm.service.keytab rm/hadoop103"
kadmin -padmin/admin -wadmin -q"addprinc -randkey dn/hadoop103"
kadmin -padmin/admin -wadmin -q"xst -k /etc/security/keytab/dn.service.keytab dn/hadoop103"
kadmin -padmin/admin -wadmin -q"addprinc -randkey nm/hadoop103"
kadmin -padmin/admin -wadmin -q"xst -k /etc/security/keytab/nm.service.keytab nm/hadoop103"
kadmin -padmin/admin -wadmin -q"addprinc -randkey HTTP/hadoop103"
kadmin -padmin/admin -wadmin -q"xst -k /etc/security/keytab/spnego.service.keytab HTTP/hadoop103"
# ==========以下命令在hadoop104节点执行============
kadmin -padmin/admin -wadmin -q"addprinc -randkey dn/hadoop104"
kadmin -padmin/admin -wadmin -q"xst -k /etc/security/keytab/dn.service.keytab dn/hadoop104"
kadmin -padmin/admin -wadmin -q"addprinc -randkey sn/hadoop104"
kadmin -padmin/admin -wadmin -q"xst -k /etc/security/keytab/sn.service.keytab sn/hadoop104"
kadmin -padmin/admin -wadmin -q"addprinc -randkey nm/hadoop104"
kadmin -padmin/admin -wadmin -q"xst -k /etc/security/keytab/nm.service.keytab nm/hadoop104"
kadmin -padmin/admin -wadmin -q"addprinc -randkey HTTP/hadoop104"
kadmin -padmin/admin -wadmin -q"xst -k /etc/security/keytab/spnego.service.keytab HTTP/hadoop104"
# ==========修改所有节点keytab文件的所有者和访问权限============
# 三台机器依次执行
chown -R root:hadoop /etc/security/keytab/
chmod 660 /etc/security/keytab/*
2.2 修改Hadoop配置文件
需要修改的内容如下(添加),修改完毕需要分发所改文件
vim /opt/module/hadoop-3.1.3/etc/hadoop/core-site.xml
<!-- Kerberos主体到系统用户的映射机制 -->
<property>
<name>hadoop.security.auth_to_local.mechanism</name>
<value>MIT</value>
</property>
<!-- RULE:[<规则编号>:<规则表达式>](<匹配的Kerberos主体>)s/<替换表达式>/<本地用户名称>/ -->
<!-- Kerberos主体到系统用户的具体映射规则, -->
<!-- 默认规则会将未匹配的Kerberos主体映射为其原始名称 -->
<property>
<name>hadoop.security.auth_to_local</name>
<value>
RULE:[2:$1/$2@$0]([ndj]n\/.*@EXAMPLE\.COM)s/.*/hdfs/
RULE:[2:$1/$2@$0]([rn]m\/.*@EXAMPLE\.COM)s/.*/yarn/
RULE:[2:$1/$2@$0](jhs\/.*@EXAMPLE\.COM)s/.*/mapred/
DEFAULT
</value>
</property>
<!-- 启用Hadoop集群Kerberos安全认证 -->
<property>
<name>hadoop.security.authentication</name>
<value>kerberos</value>
</property>
<!-- 启用Hadoop集群授权管理 -->
<property>
<name>hadoop.security.authorization</name>
<value>true</value>
</property>
<!-- Hadoop集群间RPC通讯设为仅认证模式 -->
<property>
<name>hadoop.rpc.protection</name>
<value>authentication</value>
</property>
vim /opt/module/hadoop-3.1.3/etc/hadoop/hdfs-site.xml
<!-- 访问DataNode数据块时需通过Kerberos认证 -->
<property>
<name>dfs.block.access.token.enable</name>
<value>true</value>
</property>
<!-- NameNode服务的Kerberos主体,_HOST会自动解析为服务所在的主机名 -->
<property>
<name>dfs.namenode.kerberos.principal</name>
<value>nn/_HOST@EXAMPLE.COM</value>
</property>
<!-- NameNode服务的Kerberos密钥文件路径 -->
<property>
<name>dfs.namenode.keytab.file</name>
<value>/etc/security/keytab/nn.service.keytab</value>
</property>
<!-- Secondary NameNode服务的Kerberos密钥文件路径 -->
<property>
<name>dfs.secondary.namenode.keytab.file</name>
<value>/etc/security/keytab/sn.service.keytab</value>
</property>
<!-- Secondary NameNode服务的Kerberos主体 -->
<property>
<name>dfs.secondary.namenode.kerberos.principal</name>
<value>sn/_HOST@EXAMPLE.COM</value>
</property>
<!-- NameNode Web服务的Kerberos主体 -->
<property>
<name>dfs.namenode.kerberos.internal.spnego.principal</name>
<value>HTTP/_HOST@EXAMPLE.COM</value>
</property>
<!-- WebHDFS REST服务的Kerberos主体 -->
<property>
<name>dfs.web.authentication.kerberos.principal</name>
<value>HTTP/_HOST@EXAMPLE.COM</value>
</property>
<!-- Secondary NameNode Web UI服务的Kerberos主体 -->
<property>
<name>dfs.secondary.namenode.kerberos.internal.spnego.principal</name>
<value>HTTP/_HOST@EXAMPLE.COM</value>
</property>
<!-- Hadoop Web UI的Kerberos密钥文件路径 -->
<property>
<name>dfs.web.authentication.kerberos.keytab</name>
<value>/etc/security/keytab/spnego.service.keytab</value>
</property>
<!-- DataNode服务的Kerberos主体 -->
<property>
<name>dfs.datanode.kerberos.principal</name>
<value>dn/_HOST@EXAMPLE.COM</value>
</property>
<!-- DataNode服务的Kerberos密钥文件路径 -->
<property>
<name>dfs.datanode.keytab.file</name>
<value>/etc/security/keytab/dn.service.keytab</value>
</property>
<!-- 配置NameNode Web UI 使用HTTPS协议 -->
<property>
<name>dfs.http.policy</name>
<value>HTTPS_ONLY</value>
</property>
<!-- 配置DataNode数据传输保护策略为仅认证模式 -->
<property>
<name>dfs.data.transfer.protection</name>
<value>authentication</value>
</property>
vim /opt/module/hadoop-3.1.3/etc/hadoop/yarn-site.xml
<!-- Resource Manager 服务的Kerberos主体 -->
<property>
<name>yarn.resourcemanager.principal</name>
<value>rm/_HOST@EXAMPLE.COM</value>
</property>
<!-- Resource Manager 服务的Kerberos密钥文件 -->
<property>
<name>yarn.resourcemanager.keytab</name>
<value>/etc/security/keytab/rm.service.keytab</value>
</property>
<!-- Node Manager 服务的Kerberos主体 -->
<property>
<name>yarn.nodemanager.principal</name>
<value>nm/_HOST@EXAMPLE.COM</value>
</property>
<!-- Node Manager 服务的Kerberos密钥文件 -->
<property>
<name>yarn.nodemanager.keytab</name>
<value>/etc/security/keytab/nm.service.keytab</value>
</property>
vim /opt/module/hadoop-3.1.3/etc/hadoop/mapred-site.xml
<!-- 历史服务器的Kerberos主体 -->
<property>
<name>mapreduce.jobhistory.keytab</name>
<value>/etc/security/keytab/jhs.service.keytab</value>
</property>
<!-- 历史服务器的Kerberos密钥文件 -->
<property>
<name>mapreduce.jobhistory.principal</name>
<value>jhs/_HOST@EXAMPLE.COM</value>
</property>
最后分发四个文件
xsync /opt/module/hadoop-3.1.3/etc/hadoop/core-site.xml
xsync /opt/module/hadoop-3.1.3/etc/hadoop/hdfs-site.xml
xsync /opt/module/hadoop-3.1.3/etc/hadoop/yarn-site.xml
xsync /opt/module/hadoop-3.1.3/etc/hadoop/mapred-site.xml
2.3 配置HDFS使用HTTPS安全传输协议
# Keytool是java数据证书的管理工具,使用户能够管理自己的公/私钥对及相关证书。
# -keystore 指定密钥库的名称及位置(产生的各类信息将存在.keystore文件中)
# -genkey(或者-genkeypair) 生成密钥对
# -alias 为生成的密钥对指定别名,如果没有默认是mykey
# -keyalg 指定密钥的算法 RSA/DSA 默认是DSA
keytool -keystore /etc/security/keytab/keystore -alias jetty -genkey -keyalg RSA
keytool -keystore keystore -list
# 修改keystore文件的所有者和访问权限
chown -R root:hadoop /etc/security/keytab/keystore
chmod 660 /etc/security/keytab/keystore
# 密钥库的密码至少6个字符,可以是纯数字或者字母或者数字和字母的组合等等
# 确保hdfs用户(HDFS的启动用户)具有对所生成keystore文件的读权限
# 将该证书分发到集群中的每台节点的相同路径
xsync /etc/security/keytab/keystore
# 然后修改hadoop配置文件ssl-server.xml.example
mv $HADOOP_HOME/etc/hadoop/ssl-server.xml.example $HADOOP_HOME/etc/hadoop/ssl-server.xml
vim $HADOOP_HOME/etc/hadoop/ssl-server.xml
# 修改如下
<!-- SSL密钥库路径 -->
<property>
<name>ssl.server.keystore.location</name>
<value>/etc/security/keytab/keystore</value>
</property>
<!-- SSL密钥库密码 -->
<property>
<name>ssl.server.keystore.password</name>
<value>123456</value>
</property>
<!-- SSL可信任密钥库路径 -->
<property>
<name>ssl.server.truststore.location</name>
<value>/etc/security/keytab/keystore</value>
</property>
<!-- SSL密钥库中密钥的密码 -->
<property>
<name>ssl.server.keystore.keypassword</name>
<value>123456</value>
</property>
<!-- SSL可信任密钥库密码 -->
<property>
<name>ssl.server.truststore.password</name>
<value>123456</value>
</property>
最后分发xsync $HADOOP_HOME/etc/hadoop/ssl-server.xml
2.4 配置Yarn使用LinuxContainerExecutor
因为默认提交任务的用户是启动hadoop的用户,因此需要把它改为提交者的用户
修改所有节点的container-executor所有者和权限,要求其所有者为root,所有组为hadoop(启动NodeManger的yarn用户的所属组),权限为6050。其默认路径为$HADOOP_HOME/bin
# 三台机器依次执行
chown root:hadoop /opt/module/hadoop-3.1.3/bin/container-executor
chmod 6050 /opt/module/hadoop-3.1.3/bin/container-executor
# 三台节点依次修改
# 修改所有节点的container-executor.cfg文件的所有者和权限,
# 要求该文件及其所有的上级目录的所有者均为root,所有组为hadoop(启动NodeManger的yarn用户的所属组),权限为400。
# 其默认路径为$HADOOP_HOME/etc/hadoop
chown root:hadoop /opt/module/hadoop-3.1.3/etc/hadoop/container-executor.cfg
chown root:hadoop /opt/module/hadoop-3.1.3/etc/hadoop
chown root:hadoop /opt/module/hadoop-3.1.3/etc
chown root:hadoop /opt/module/hadoop-3.1.3
chown root:hadoop /opt/module
chmod 400 /opt/module/hadoop-3.1.3/etc/hadoop/container-executor.cfg
# 修改$HADOOP_HOME/etc/hadoop/container-executor.cfg
vim $HADOOP_HOME/etc/hadoop/container-executor.cfg
# 内容如下
yarn.nodemanager.linux-container-executor.group=hadoop
banned.users=hdfs,yarn,mapred
min.user.id=1000
allowed.system.users=
feature.tc.enabled=false
修改$HADOOP_HOME/etc/hadoop/yarn-site.xml文件,vim $HADOOP_HOME/etc/hadoop/yarn-site.xml,增加内容
<!-- 配置Node Manager使用LinuxContainerExecutor管理Container -->
<property>
<name>yarn.nodemanager.container-executor.class</name>
<value>org.apache.hadoop.yarn.server.nodemanager.LinuxContainerExecutor</value>
</property>
<!-- 配置Node Manager的启动用户的所属组 -->
<property>
<name>yarn.nodemanager.linux-container-executor.group</name>
<value>hadoop</value>
</property>
<!-- LinuxContainerExecutor脚本路径 -->
<property>
<name>yarn.nodemanager.linux-container-executor.path</name>
<value>/opt/module/hadoop-3.1.3/bin/container-executor</value>
</property>
最后分发
xsync $HADOOP_HOME/etc/hadoop/container-executor.cfg
xsync $HADOOP_HOME/etc/hadoop/yarn-site.xml
3、安全模式下启动Hadoop集群
3.1 修改特定本地路径权限
因为是不同的用户分别启动不同的程序,所以需要修改之前的所有者和权限
| local | $HADOOP_LOG_DIR | hdfs:hadoop | drwxrwxr-x |
|---|---|---|---|
| local | dfs.namenode.name.dir | hdfs:hadoop | drwx------ |
| local | dfs.datanode.data.dir | hdfs:hadoop | drwx------ |
| local | dfs.namenode.checkpoint.dir | hdfs:hadoop | drwx------ |
| local | yarn.nodemanager.local-dirs | yarn:hadoop | drwxrwxr-x |
| local | yarn.nodemanager.log-dirs | yarn:hadoop | drwxrwxr-x |
# $HADOOP_LOG_DIR(所有节点),三台机器依次运行
# 该变量位于hadoop-env.sh文件,默认值为 ${HADOOP_HOME}/logs
chown hdfs:hadoop /opt/module/hadoop-3.1.3/logs/
chmod 775 /opt/module/hadoop-3.1.3/logs/
# dfs.namenode.name.dir(NameNode节点),102机器
# 该参数位于hdfs-site.xml文件,默认值为file://${hadoop.tmp.dir}/dfs/name
chown -R hdfs:hadoop /opt/module/hadoop-3.1.3/data/dfs/name/
chmod 700 /opt/module/hadoop-3.1.3/data/dfs/name/
# dfs.datanode.data.dir(DataNode节点),三台机器
# 该参数为于hdfs-site.xml文件,默认值为file://${hadoop.tmp.dir}/dfs/data
chown -R hdfs:hadoop /opt/module/hadoop-3.1.3/data/dfs/data/
chmod 700 /opt/module/hadoop-3.1.3/data/dfs/data/
# dfs.namenode.checkpoint.dir(SecondaryNameNode节点),104机器
# 该参数位于hdfs-site.xml文件,默认值为file://${hadoop.tmp.dir}/dfs/namesecondary
chown -R hdfs:hadoop /opt/module/hadoop-3.1.3/data/dfs/namesecondary/
chmod 700 /opt/module/hadoop-3.1.3/data/dfs/namesecondary/
# yarn.nodemanager.local-dirs(NodeManager节点),三台机器
# 该参数位于yarn-site.xml文件,默认值为file://${hadoop.tmp.dir}/nm-local-dir
chown -R yarn:hadoop /opt/module/hadoop-3.1.3/data/nm-local-dir/
chmod -R 775 /opt/module/hadoop-3.1.3/data/nm-local-dir/
# yarn.nodemanager.log-dirs(NodeManager节点),三台机器
# 该参数位于yarn-site.xml文件,默认值为$HADOOP_LOG_DIR/userlogs
chown yarn:hadoop /opt/module/hadoop-3.1.3/logs/userlogs/
chmod 775 /opt/module/hadoop-3.1.3/logs/userlogs/
3.2 启动HDFS
# =================== 单点启动 ================
# -i:重新加载环境变量
# -u:以特定用户的身份执行后续命令
# 启动NameNode,102机器启动
sudo -i -u hdfs hdfs --daemon start namenode
# 启动DataNode,三台机器依次启动
sudo -i -u hdfs hdfs --daemon start datanode
# 启动SecondaryNameNode,104机器启动
sudo -i -u hdfs hdfs --daemon start secondarynamenode
# =================== 群起 ===================
# 在主节点(hadoop102)配置hdfs用户到所有节点的免密登录。
su hdfs
ssh-keygen
# 输入密码hdfs设置免密登陆
ssh-copy-id hadoop102
ssh-copy-id hadoop103
ssh-copy-id hadoop104
exit
# 修改主节点(hadoop102)节点的$HADOOP_HOME/sbin/start-dfs.sh脚本,在顶部增加以下环境变量
vim $HADOOP_HOME/sbin/start-dfs.sh
# 在顶部增加如下内容
HDFS_DATANODE_USER=hdfs
HDFS_NAMENODE_USER=hdfs
HDFS_SECONDARYNAMENODE_USER=hdfs
# 注:$HADOOP_HOME/sbin/stop-dfs.sh也需在顶部增加上述环境变量才可使用
# 以root用户执行群起脚本,即可启动HDFS集群
start-dfs.sh
# 查看HFDS web页面
# 访问地址为https://hadoop102:9871
3.3 改HDFS特定路径访问权限
| hdfs | / | hdfs:hadoop | drwxr-xr-x |
|---|---|---|---|
| hdfs | /tmp | hdfs:hadoop | drwxrwxrwxt |
| hdfs | /user | hdfs:hadoop | drwxrwxr-x |
| hdfs | yarn.nodemanager.remote-app-log-dir | yarn:hadoop | drwxrwxrwxt |
| hdfs | mapreduce.jobhistory.intermediate-done-dir | mapred:hadoop | drwxrwxrwxt |
| hdfs | mapreduce.jobhistory.done-dir | mapred:hadoop | drwxrwx— |
若上述路径不存在,需手动创建
# 以下操作都在hadoop102
# (1)创建hdfs/hadoop主体,执行以下命令并按照提示输入密码
kadmin.local -q "addprinc hdfs/hadoop"
# (2)认证hdfs/hadoop主体,执行以下命令并按照提示输入密码
kinit hdfs/hadoop
# 按照上述要求修改指定路径的所有者和权限
# 修改/、/tmp、/user路径
hadoop fs -chown hdfs:hadoop / /tmp /user
hadoop fs -chmod 755 /
hadoop fs -chmod 1777 /tmp
hadoop fs -chmod 775 /user
# 参数yarn.nodemanager.remote-app-log-dir位于yarn-site.xml文件,默认值/tmp/logs
hadoop fs -chown yarn:hadoop /tmp/logs
hadoop fs -chmod 1777 /tmp/logs
# (3)参数mapreduce.jobhistory.intermediate-done-dir位于mapred-site.xml文件,
# 默认值为/tmp/hadoop-yarn/staging/history/done_intermediate,需保证该路径的所有上级目录(除/tmp)的所有者均为mapred,所属组为hadoop,权限为770
hadoop fs -chown -R mapred:hadoop /tmp/hadoop-yarn/staging/history/done_intermediate
hadoop fs -chmod -R 1777 /tmp/hadoop-yarn/staging/history/done_intermediate
hadoop fs -chown mapred:hadoop /tmp/hadoop-yarn/staging/history/
hadoop fs -chown mapred:hadoop /tmp/hadoop-yarn/staging/
hadoop fs -chown mapred:hadoop /tmp/hadoop-yarn/
hadoop fs -chmod 770 /tmp/hadoop-yarn/staging/history/
hadoop fs -chmod 770 /tmp/hadoop-yarn/staging/
hadoop fs -chmod 770 /tmp/hadoop-yarn/
# (4)参数mapreduce.jobhistory.done-dir位于mapred-site.xml文件,默认值为/tmp/hadoop-yarn/staging/history/done,
# 需保证该路径的所有上级目录(除/tmp)的所有者均为mapred,所属组为hadoop,权限为770
hadoop fs -chown -R mapred:hadoop /tmp/hadoop-yarn/staging/history/done
hadoop fs -chmod -R 750 /tmp/hadoop-yarn/staging/history/done
hadoop fs -chown mapred:hadoop /tmp/hadoop-yarn/staging/history/
hadoop fs -chown mapred:hadoop /tmp/hadoop-yarn/staging/
hadoop fs -chown mapred:hadoop /tmp/hadoop-yarn/
hadoop fs -chmod 770 /tmp/hadoop-yarn/staging/history/
hadoop fs -chmod 770 /tmp/hadoop-yarn/staging/
hadoop fs -chmod 770 /tmp/hadoop-yarn/
3.4 启动Yarn
# ==============单点启动================
# 启动ResourceManager
sudo -i -u yarn yarn --daemon start resourcemanager
# 启动NodeManager
sudo -i -u yarn yarn --daemon start nodemanager
sudo -i -u yarn yarn --daemon start nodemanager
sudo -i -u yarn yarn --daemon start nodemanager
# =================群起=====================
# 在Yarn主节点(hadoop103)配置yarn用户到所有节点的免密登录
# 修改主节点(hadoop103)的$HADOOP_HOME/sbin/start-yarn.sh,在顶部增加以下环境变量
vim $HADOOP_HOME/sbin/start-yarn.sh
# 在顶部增加如下内容
YARN_RESOURCEMANAGER_USER=yarn
YARN_NODEMANAGER_USER=yarn
# 注:stop-yarn.sh也需在顶部增加上述环境变量才可使用。
# 以root用户执行$HADOOP_HOME/sbin/start-yarn.sh脚本即可启动yarn集群。
start-yarn.sh
# 访问Yarn web页面
# 访问地址为http://hadoop103:8088
3.5 启动HistoryServer
# 启动历史服务器
sudo -i -u mapred mapred --daemon start historyserver
# 查看历史服务器web页面
# 访问地址为http://hadoop102:19888
4、启动遇坑详解
4.1 DataNode无法连接上NameNode 提示 : GSS initiate failed
# 查看namenode的报错信息
2022-03-28 17:57:11,389 WARN SecurityLogger.org.apache.hadoop.ipc.Server: Auth failed for 192.168.31.213:44542:null (GSS initiate failed) with true cause: (GSS initiate failed)
2022-03-28 17:57:14,706 WARN SecurityLogger.org.apache.hadoop.ipc.Server: Auth failed for 192.168.31.213:34648:null (GSS initiate failed) with true cause: (GSS initiate failed)
原因是JDK没有装JCE组件, JDK需要下载安装JCE组件. 重启服务即可;或者使用使用JDK 1.8.0_161或更高版本时,不需要再安装JCE Policy File,因为JDK 1.8.0_161默认启用无限强度加密。
# JCE的安装
# 官网:http://www.oracle.com/technetwork/java/javase/downloads/jce8-download-2133166.html
# 随便找一个目录, 解压 unzip jce_policy-8.zip , 获取到UnlimitedJCEPolicyJDK8文件夹
# 解压
unzip jce_policy-8.zip
# 查看文件
ll UnlimitedJCEPolicyJDK8/
# 备份 ${JAVA_HOME}/jre/lib/security目录
cd ${JAVA_HOME}
cp -r ${JAVA_HOME}/jre/lib/security ${JAVA_HOME}/jre/lib/security_bak
# 把UnlimitedJCEPolicyJDK8目录下的所有jar包(US_export_policy.jar和local_policy.jar)拷贝至集群所有节点的${JAVA_HOME}/jre/lib/security目录下
cp UnlimitedJCEPolicyJDK8/*.jar ${JAVA_HOME}/jre/lib/security
# 安装完成, 重启相关服务即可(比如kerberos/hadoop相关服务)
# 启用krb5kdc和重启kerberos服务
4.2 Hadoop集成kerberos后,报错:AccessControlException
# 报错信息
klist
Ticket cache: KEYRING:persistent:0:krb_ccache_MkHX3zi
Default principal: hdfs/hadoop102@EXAMPLE.COM
Valid starting Expires Service principal
2022-03-28T17:35:19 2022-03-29T17:35:19 krbtgt/EXAMPLE.COM@EXAMPLE.COM
hadoop fs -ls /
2022-03-28 20:23:27,667 WARN ipc.Client: Exception encountered while connecting to the server : org.apache.hadoop.security.AccessControlException: Client cannot authenticate via:[TOKEN, KERBEROS]
ls: DestHost:destPort hadoop102:8020 , LocalHost:localPort master01/192.xx.xx:0. Failed on local exception: java.io.IOException: org.apache.hadoop.security.AccessControlException: Client cannot authenticate via:[TOKEN, KERBEROS]
解决方法:修改 Kerboeros配置文件 /etc/krb5.conf , 注释掉 : default_ccache_name 属性,然后执行kdestroy,重新kinit
可以参考:https://blog.csdn.net/zhanglong_4444/article/details/115268262
5、安全集群使用说明
5.1 用户要求
以下使用说明均基于普通用户,安全集群对用户有以下要求:
- 集群中的每个节点都需要创建该用户
- 该用户需要属于hadoop用户组
- 需要创建该用户对应的Kerberos主体
# 创建用户(存在可跳过),须在所有节点执行
useradd shawn
echo shawn| passwd --stdin shawn
# 加入hadoop组,须在所有节点执行
usermod -a -G hadoop shawn
# 创建主体,直接输入账户和密码
kadmin -p admin/admin -wadmin -q"addprinc -pw shawn shawn"
5.2 访问HDFS集群文件
首先针对是shell环境
# 认证
kinit shawn
# 查看当前认证用户
klist
# 查看
hadoop fs -ls /
# 注销认证
kdestroy
# 再次查看,发现报错没有认证
hadoop fs -ls /
对于web页面
# 下载认证客户端(windows),然后安装好
# http://web.mit.edu/kerberos/dist/kfw/4.1/kfw-4.1-amd64.msi
# 编辑C:\ProgramData\MIT\Kerberos5\krb5.ini文件
# 内容如下
[libdefaults]
dns_lookup_realm = false
ticket_lifetime = 24h
forwardable = true
rdns = false
default_realm = EXAMPLE.COM
[realms]
EXAMPLE.COM = {
kdc = hadoop102
admin_server = hadoop102
}
[domain_realm]
配置火狐浏览器(其他浏览器有可能有问题),打开浏览器,在地址栏输入about:config,点击回车;搜索network.negotiate-auth.trusted-uris,修改值为要访问的主机名(hadoop102);下一步搜索network.auth.use-sspi,双击将值变为false
最后启动认证,启动Kerberos客户端,点击Get Ticket,输入主体名和密码,点击OK,认证成功,访问web界面
5.3 提交MapReduce任务
# 认证
kinit shawn
# 提交任务
hadoop jar /opt/module/hadoop-3.1.3/share/hadoop/mapreduce/hadoop-mapreduce-examples-3.1.3.jar pi 1 1
三、Hive安全认证
1、Hive用户认证配置
1.1 创建Hive系统用户和Kerberos主体
hive作为服务来进行Kerberos认证
# 创建系统用户,三台机器都要创建
useradd hive -g hadoop
echo hive | passwd --stdin hive
# 创建Kerberos主体并生成keytab文件,在hadoop102创建
# 创建hive用户的Kerberos主体
kadmin -padmin/admin -wadmin -q"addprinc -randkey hive/hadoop102"
# 在Hive所部署的节点生成keytab文件
kadmin -padmin/admin -wadmin -q"xst -k /etc/security/keytab/hive.service.keytab hive/hadoop102"
# 修改keytab文件所有者和访问权限
chown -R root:hadoop /etc/security/keytab/
chmod 660 /etc/security/keytab/hive.service.keytab
1.2 配置认证
修改$HIVE_HOME/conf/hive-site.xml文件,vim $HIVE_HOME/conf/hive-site.xml,增加如下属性
<!-- HiveServer2启用Kerberos认证 -->
<property>
<name>hive.server2.authentication</name>
<value>kerberos</value>
</property>
<!-- HiveServer2服务的Kerberos主体 -->
<property>
<name>hive.server2.authentication.kerberos.principal</name>
<value>hive/hadoop102@EXAMPLE.COM</value>
</property>
<!-- HiveServer2服务的Kerberos密钥文件 -->
<property>
<name>hive.server2.authentication.kerberos.keytab</name>
<value>/etc/security/keytab/hive.service.keytab</value>
</property>
<!-- Metastore启动认证 -->
<property>
<name>hive.metastore.sasl.enabled</name>
<value>true</value>
</property>
<!-- Metastore Kerberos密钥文件 -->
<property>
<name>hive.metastore.kerberos.keytab.file</name>
<value>/etc/security/keytab/hive.service.keytab</value>
</property>
<!-- Metastore Kerberos主体 -->
<property>
<name>hive.metastore.kerberos.principal</name>
<value>hive/hadoop102@EXAMPLE.COM</value>
</property>
修改$HADOOP_HOME/etc/hadoop/core-site.xml文件,vim $HADOOP_HOME/etc/hadoop/core-site.xml
删除以下参数
<property>
<name>hadoop.http.staticuser.user</name>
<value>atguigu</value>
</property>
<property>
<name>hadoop.proxyuser.atguigu.hosts</name>
<value>*</value>
</property>
<property>
<name>hadoop.proxyuser.atguigu.groups</name>
<value>*</value>
</property>
<property>
<name>hadoop.proxyuser.atguigu.users</name>
<value>*</value>
</property>
增加以下参数
<property>
<name>hadoop.proxyuser.hive.hosts</name>
<value>*</value>
</property>
<property>
<name>hadoop.proxyuser.hive.groups</name>
<value>*</value>
</property>
<property>
<name>hadoop.proxyuser.hive.users</name>
<value>*</value>
</property>
# 分发配置core-site.xml文件
xsync $HADOOP_HOME/etc/hadoop/core-site.xml
# 重启Hadoop集群
stop-dfs.sh
stop-yarn.sh
start-dfs.sh
start-yarn.sh
1.3 启动hiveserver2
# 注:需使用hive用户启动
sudo -i -u hive hiveserver2
2、Hive Kerberos认证使用说明
以下说明均基于普通用户
2.1 beeline客户端
# 认证,执行以下命令,并按照提示输入密码
kinit shawn
# 使用beeline客户端连接hiveserver2
beeline
# 使用如下url进行连接
!connect jdbc:hive2://hadoop102:10000/;principal=hive/hadoop102@EXAMPLE.COM
# 测试查询
2.2 DataGrip客户端
jar包获取:https://download.csdn.net/download/lemon_TT/87951242
首先需要新建driver(自带的没有认证功能),配置Driver,url模板:jdbc:hive2://{host}:{port}/{database}[;<;,{:identifier}={:param}>](注意jar包路径)

第二步新建连接,选择刚刚创建的driver,选择配置连接,url:jdbc:hive2://hadoop102:10000/;principal=hive/hadoop102@EXAMPLE.COM
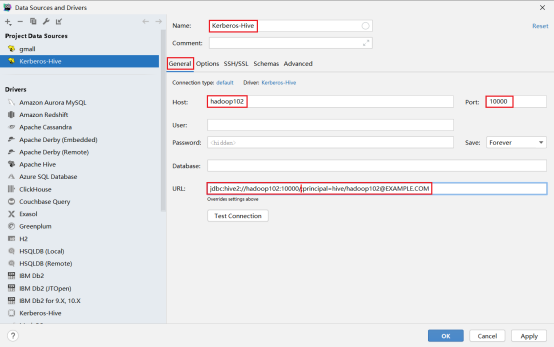
选择高级配置,配置参数,注意路径要有文件
-Djava.security.krb5.conf="C:\\ProgramData\\MIT\\Kerberos5\\krb5.ini"
-Djava.security.auth.login.config="C:\\ProgramData\\MIT\\Kerberos5\\shawn.conf"
-Djavax.security.auth.useSubjectCredsOnly=false
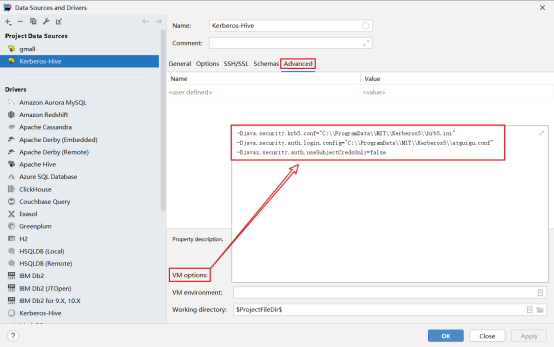
编写JAAS(Java认证授权服务)配置文件,内容如下,文件名和路径须和上图中java.security.auth.login.config参数的值保持一致。
com.sun.security.jgss.initiate{
com.sun.security.auth.module.Krb5LoginModule required
useKeyTab=true
useTicketCache=false
keyTab="C:\\ProgramData\\MIT\\Kerberos5\\shawn.keytab"
principal="shawn@EXAMPLE.COM";
};
为用户生成keytab文件,在krb5kdc所在节点(hadoop102)执行以下命令,然后将生成的atguigu.keytab文件,置于Windows中的特定路径,测试连接
kadmin.local -q"xst -norandkey -k /home/shawn/shawn.keytab shawn"
四、安全环境实战
Hadoop启用Kerberos安全认证之后,之前的非安全环境下的全流程调度脚本和即席查询引擎均会遇到认证问题,故需要对其进行改进,本章内容仅限参考,具体可以参考官网
1、数仓全流程改造
此处统一将数仓的全部数据资源的所有者设为hive用户,全流程的每步操作均认证为hive用户
1.1 用户准备
# 在各节点创建hive用户,如已存在则跳过,三个节点
useradd hive -g hadoop
echo hive | passwd --stdin hive
# 为hive用户创建Keberos主体,102节点
# 创建主体
kadmin -padmin/admin -wadmin -q"addprinc -randkey hive"
# 生成keytab文件
kadmin -padmin/admin -wadmin -q"xst -k /etc/security/keytab/hive.keytab hive"
# 修改keytab文件所有者和访问权限
chown hive:hadoop /etc/security/keytab/hive.keytab
chmod 440 /etc/security/keytab/hive.keytab
# 分发keytab文件
xsync /etc/security/keytab/hive.keytab
1.2 数据采集通道修改
# 修改/opt/module/flume/conf/kafka-flume-hdfs.conf配置文件,
vim /opt/module/flume/conf/kafka-flume-hdfs.conf
# 增加以下参数
a1.sinks.k1.hdfs.kerberosPrincipal=hive@EXAMPLE.COM
a1.sinks.k1.hdfs.kerberosKeytab=/etc/security/keytab/hive.keytab
# 业务数据
# 修改sqoop每日同步脚本/home/atguigu/bin/mysql_to_hdfs.sh
# 在顶部增加如下认证语句,shell脚本都可以如此认证
kinit -kt /etc/security/keytab/hive.keytab hive
# 数仓各层脚本均需在顶部加入如下认证语句
kinit -kt /etc/security/keytab/hive.keytab hive
# 举例
# 表示将text内容加入到file文件的第1行之后
sed -i '1 a kinit -kt /etc/security/keytab/hive.keytab hive' hdfs_to_ods_log.sh
1.3 修改HDFS特定路径所有者
# 认证为hdfs用户,执行以下命令并按提示输入密码
kinit hdfs/hadoop
# 修改数据采集目标路径
hadoop fs -chown -R hive:hadoop /origin_data
hadoop fs -chown -R hive:hadoop /warehouse
# 修改hive家目录/user/hive
hadoop fs -chown -R hive:hadoop /user/hive
# 修改spark.eventLog.dir路径
hadoop fs -chown -R hive:hadoop /spark-history
1.4 Azkaban举例
# 在各节点创建azkaban用户
useradd azkaban -g hadoop
echo azkaban | passwd --stdin azkaban
# 将各节点Azkaban安装路径所有者改为azkaban用户
chown -R azkaban:hadoop /opt/module/azkaban
# 使用azkaban用户启动Azkaban
# 在各节点执行以下命令,启动Executor
sudo -i -u azkaban bash -c "cd /opt/module/azkaban/azkaban-exec;bin/start-exec.sh"
# 激活Executor Server,任选一台节点执行以下激活命令即可
curl http://hadoop102:12321/executor?action=activate
curl http://hadoop103:12321/executor?action=activate
curl http://hadoop104:12321/executor?action=activate
# 启动Web Server
sudo -i -u azkaban bash -c "cd /opt/module/azkaban/azkaban-web;bin/start-web.sh"
# 修改数仓各层脚本访问权限,确保azkaban用户能够访问到,三台机器都设置
chown -R atguigu:hadoop /home/atguigu
chmod 770 /home/atguigu
2、即席查询之Presto
2.1 改动说明
Presto集群开启Kerberos认证可只配置Presto Coordinator和Presto Cli之间进行认证,集群内部通讯可不进行认证。Presto Coordinator和Presto Cli之间的认证要求两者采用更为安全的HTTPS协议进行通讯。
若Presto对接的是Hive数据源,由于其需要访问Hive的元数据和HDFS上的数据文件,故也需要对Hive Connector进行Kerberos认证
2.2 用户准备
# 在所有节点创建presto系统用户
useradd presto -g hadoop
echo presto | passwd --stdin presto
# 为Hive Connector创建Kerberos主体,hadoop102节点
# 创建presto用户的Kerberos主体
kadmin -padmin/admin -wadmin -q"addprinc -randkey presto"
# 生成keytab文件
kadmin -padmin/admin -wadmin -q"xst -k /etc/security/keytab/presto.keytab presto"
# 修改keytab文件的访问权限
chown presto:hadoop /etc/security/keytab/presto.keytab
# 分发keytab文件
xsync /etc/security/keytab/presto.keytab
# 为Presto Coordinator创建Kerberos主体,HADOOP102节点
# 创建presto用户的Kerberos主体
kadmin -padmin/admin -wadmin -q"addprinc -randkey presto/hadoop102"
# 生成keytab文件
kadmin -padmin/admin -wadmin -q"xst -k /etc/security/keytab/presto.service.keytab presto/hadoop102"
# 修改keytab文件的访问权限
chown presto:hadoop /etc/security/keytab/presto.service.keytab
2.3 创建HTTPS协议所需的密钥对
# 注意:
# (1)alias(别名)需要和Presto Coordinator的Kerberos主体名保持一致
# (2)名字与姓氏 需要填写Coordinator所在的主机名
# 使用Java提供的keytool工具生成密钥对
keytool -genkeypair -alias presto -keyalg RSA -keystore /etc/security/keytab/keystore.jks
# 您的名字与姓氏是什么?
# [Unknown]: hadoop102
# 修改keystore文件的所有者和访问权限
chown presto:hadoop /etc/security/keytab/keystore.jks
chmod 660 /etc/security/keytab/keystore.jks
2.4 修改Presto Coordinator配置文件
在/opt/module/presto/etc/config.properties文件中增加以下参数
http-server.authentication.type=KERBEROS
http.server.authentication.krb5.service-name=presto
http.server.authentication.krb5.keytab=/etc/security/keytab/presto.service.keytab
http.authentication.krb5.config=/etc/krb5.conf
http-server.https.enabled=true
http-server.https.port=7778
http-server.https.keystore.path=/etc/security/keytab/keystore.jks
http-server.https.keystore.key=123456
2.5 修改Hive Connector配置文件
在/opt/module/presto/etc/catalog/hive.properties中增加以下参数
hive.metastore.authentication.type=KERBEROS
hive.metastore.service.principal=hive/hadoop102@EXAMPLE.COM
hive.metastore.client.principal=presto@EXAMPLE.COM
hive.metastore.client.keytab=/etc/security/keytab/presto.keytab
hive.hdfs.authentication.type=KERBEROS
hive.hdfs.impersonation.enabled=true
hive.hdfs.presto.principal=presto@EXAMPLE.COM
hive.hdfs.presto.keytab=/etc/security/keytab/presto.keytab
hive.config.resources=/opt/module/hadoop-3.1.3/etc/hadoop/core-site.xml,/opt/module/hadoop-3.1.3/etc/hadoop/hdfs-site.xml
分发/opt/module/presto/etc/catalog/hive.properties文件
xsync /opt/module/presto/etc/catalog/hive.properties
2.6 配置客户端Kerberos主体到用户名之间的映射规则
新建/opt/module/presto/etc/access-control.properties配置文件
access-control.name=file
security.config-file=etc/rules.json
新建/opt/module/presto/etc/rules.json文件,内容如下
{
"catalogs": [
{
"allow": true
}
],
"user_patterns": [
"(.*)",
"([a-zA-Z]+)/?.*@.*"
]
}
2.7 配置Presto代理用户
# 修改Hadoop配置文件
# 修改$HADOOP_HOME/etc/hadoop/core-site.xml配置文件,增加如下内容
vim $HADOOP_HOME/etc/hadoop/core-site.xml
<property>
<name>hadoop.proxyuser.presto.hosts</name>
<value>*</value>
</property>
<property>
<name>hadoop.proxyuser.presto.groups</name>
<value>*</value>
</property>
<property>
<name>hadoop.proxyuser.presto.users</name>
<value>*</value>
</property>
# 分发修改的文件
xsync $HADOOP_HOME/etc/hadoop/core-site.xml
# 重启Hadoop集群
stop-dfs.sh
stop-yarn.sh
start-dfs.sh
start-yarn.sh
2.8 重启Presto集群
# 关闭集群,三台机器依次执行
/opt/module/presto/bin/launcher stop
# 修改Presto安装路径所有者为presto,三台机器依次执行
chown -R presto:hadoop /opt/module/presto
# 使用hive用户启动MetaStore服务,102机器
sudo -i -u hive hive --service metastore
# 使用presto用户启动Presto集群,三台机器
sudo -i -u presto /opt/module/presto/bin/launcher
2.9 客户端认证访问Presto集群
# 102机器执行
./prestocli \
--server https://hadoop102:7778 \
--catalog hive \
--schema default \
--enable-authentication \
--krb5-remote-service-name presto \
--krb5-config-path /etc/krb5.conf \
--krb5-principal atguigu@EXAMPLE.COM \
--krb5-keytab-path /home/atguigu/atguigu.keytab \
--keystore-path /etc/security/keytab/keystore.jks \
--keystore-password 123456 \
--user atguigu
3、即席查询之Kylin
3.1 改动说明
从Kylin的架构,可以看出Kylin充当只是一个Hadoop客户端,读取Hive数据,利用MR或Spark进行计算,将Cube存储至HBase中。所以在安全的Hadoop环境下,Kylin不需要做额外的配置,只需要具备一个Kerberos主体,进行常规的认证即可
但是Kylin(这里的kylin版本为3.x)所依赖的HBase需要进行额外的配置,才能在安全的Hadoop环境下正常工作
3.2 HBase开启Kerberos认证
首先进行用户准备
# 在各节点创建hbase系统用户
useradd -g hadoop hbase
echo hbase | passwd --stdin hbase
# 创建hbase Kerberos主体
# 在hadoop102节点创建主体,生成密钥文件,并修改所有者
kadmin -padmin/admin -wadmin -q"addprinc -randkey hbase/hadoop102"
kadmin -padmin/admin -wadmin -q"xst -k /etc/security/keytab/hbase.service.keytab hbase/hadoop102"
chown hbase:hadoop /etc/security/keytab/hbase.service.keytab
# 在hadoop103节点创建主体,生成密钥文件,并修改所有者
kadmin -padmin/admin -wadmin -q"addprinc -randkey hbase/hadoop103"
kadmin -padmin/admin -wadmin -q"xst -k /etc/security/keytab/hbase.service.keytab hbase/hadoop103"
chown hbase:hadoop /etc/security/keytab/hbase.service.keytab
# 在hadoop104节点创建主体,生成密钥文件,并修改所有者
kadmin -padmin/admin -wadmin -q"addprinc -randkey hbase/hadoop104"
kadmin -padmin/admin -wadmin -q"xst -k /etc/security/keytab/hbase.service.keytab hbase/hadoop104"
chown hbase:hadoop /etc/security/keytab/hbase.service.keytab
修改HBase配置文件,修改$HBASE_HOME/conf/hbase-site.xml配置文件,增加以下参数
<property>
<name>hbase.security.authentication</name>
<value>kerberos</value>
</property>
<property>
<name>hbase.master.kerberos.principal</name>
<value>hbase/_HOST@EXAMPLE.COM</value>
</property>
<property>
<name>hbase.master.keytab.file</name>
<value>/etc/security/keytab/hbase.service.keytab</value>
</property>
<property>
<name>hbase.regionserver.kerberos.principal</name>
<value>hbase/_HOST@EXAMPLE.COM</value>
</property>
<property>
<name>hbase.regionserver.keytab.file</name>
<value>/etc/security/keytab/hbase.service.keytab</value>
</property>
<property>
<name>hbase.coprocessor.region.classes</name>
<value>org.apache.hadoop.hbase.security.token.TokenProvider</value>
</property>
# 分发配置文件
xsync $HBASE_HOME/conf/hbase-site.xml
# 修改hbase.rootdir路径所有者
# 使用hdfs/hadoop用户进行认证
kinit hdfs/hadoop
# 修改所有者
hadoop fs -chown -R hbase:hadoop /hbase
# 启动HBase
# 修改各节点HBase安装目录所有者,三台机器都修改
chown -R hbase:hadoop /opt/module/hbase
# 配置hbase用户从主节点(hadoop102)到所有节点的ssh免密
# 使用hbase用户启动HBase,hadoop102启动
sudo -i -u hbase start-hbase.sh
# 停止HBase
# 启用Kerberos认证之后,关闭HBase时,需先进行Kerberos用户认证,认证的主体为hbase。
sudo -i -u hbase kinit -kt /etc/security/keytab/hbase.service.keytab hbase/hadoop102
sudo -i -u hbase stop-hbase.sh
3.3 Kylin进行Kerberos认证
# 用户准备,创建kylin系统用户,102机器
useradd -g hadoop kylin
echo kylin | passwd --stdin kylin
# 修改kylin.env.hdfs-working-dir路径所有者为kylin
# 使用hdfs/hadoop用户进行认证
kinit hdfs/hadoop
hadoop fs -chown -R hive:hadoop /kylin
# 修改/opt/module/kylin所有者为kylin
chown -R kylin:hadoop /opt/module/kylin
# 启动kylin
# 在kylin用户下认证为hive主体
sudo -i -u kylin kinit -kt /etc/security/keytab/hive.keytab hive
# 以kylin用户的身份启动kylin
sudo -i -u kylin /opt/module/kylin/bin/kylin.sh start